리스트, 딕셔너리, 범위 자료형에 대해 이해한 내용을 바탕으로 포스팅하기
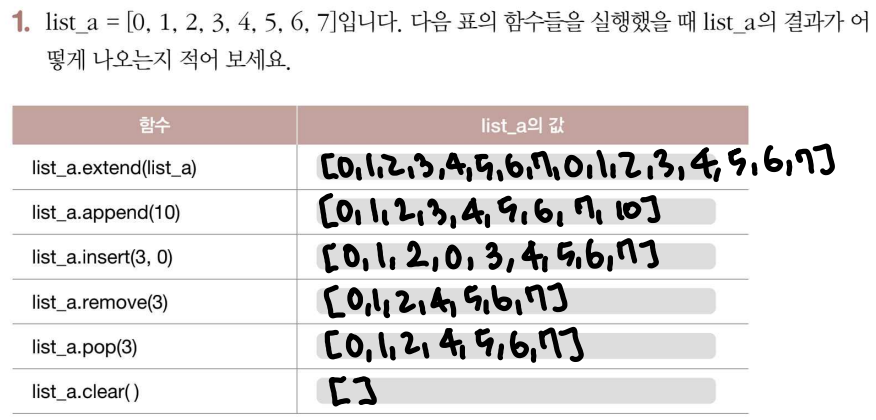
p.213쪽의 1번 문제 답 쓰고 인증샷
04-1 리스트와 반복문
* 리스트는 여러 가지 자료를 저장할 수 있는 자료이다. 파이썬에서 리스트를 생성하는 방법은 [요소, 요소, 요소...] 와 같이 대괄호 []에 자료를 쉼표로 구분해서 입력한다. 대괄호[] 내부에 넣는 자료를 요소(element)라고 부른다.

list_a = [273, 32, 103, "문자열", True, False]
273이라는 요소가 들어있는 위치는 [0] 인덱스
32라는 요소가 들어있는 위치는 [1] 인덱스
따라서 273 숫자를 불러오거나 바꾸고 싶다면 list_a[0] ="여기다 바꾸거나" 또는 list_a[0]으로 불러오면 된다.
* 리스트 사용 방법
ⓐ 대괄호 안에 음수를 넣어 뒤에서부터 요소 선택하기
>>> list_a = [273, 32, 103, "문자열", True, False]
>>> list_a[-1]
False
>>> list_a[-3]
'문자열'
ⓑ 리스트 접근 연산자를 이중으로 사용하기
위의 list_a가 있다고 할 때 list_a[3]을 지정하면 "문자열"을 꺼내오고 list_a[3][0]을 지정하면 3번째에서 가져온 "문자열"에서 다시 0번째를 가져와 출력한다.
>>> list_a = [273, 32, 103, "문자열", True, False]
>>> list_a[3]
'문자열'
>>> list_a[3][0]
'문'
ⓒ 리스트 안에 리스트를 사용하기
>>> list_a = [[1, 3, 4], [4, 5, 6], [7, 8, 9]]
>>> list_a[1]
[4,5,6]
>>> list_a[1][1]
5
* 리스트에서의 IndexError 예외
>>> list_a = [273, 32, 103, "문자열", True, False]
>>> list_a[7]
코드를 실행하면, 리스트에 [7]번째 요소가 없으므로 IndexError 예외가 발생한다.
* 리스트 연산하기 : 연결(+), 반복(*), len()

* 리스트에 요소 추가하기 : append(), insert(), extend()
append() 함수는 리스트 뒤에 요소를 추가한다.
>>> 리스트명.append(요소)
insert() 함수는 리스트의 중간에 요소를 추가한다.
>>> 리스트명.insert(위치, 요소)
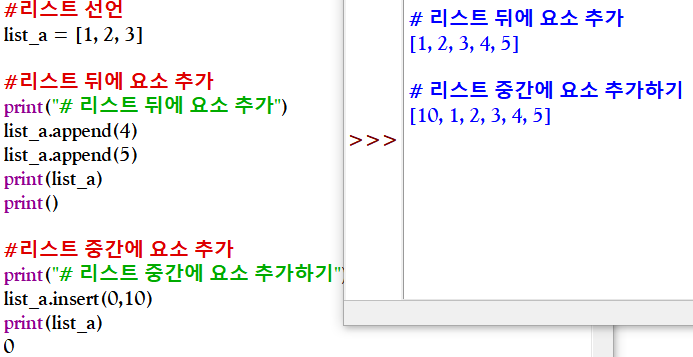
extend() 함수는 원래 리스트 뒤에 한 번에 여러 요소를 추가한다. (파괴적, 연결 연산자를 사용해서 리스트를 연결하면 원본에 어떠한 영향도 주지 않기 때문에 비파괴적)
>>> list_a = [1, 2, 3]
>>> list_a.extend([4, 5, 6])
>>> print(list_a)
[1, 2, 3, 4, 5, 6]
* 리스트에 요소 제거하기 - 인덱스로 제거하기 : del 키워드, pop()
인덱스로 제거한다는 것은 '리스트의 2번째 요소를 제거'처럼 요소의 위치를 기반으로 요소를 제거하는 것
del 리스트명[인덱스]
리스트명.pop(인덱스)
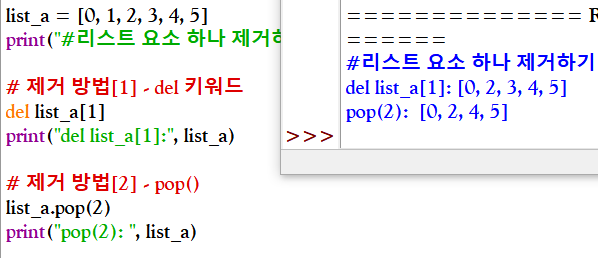
+ del 키워드로 범위를 지정해 리스트의 요소를 한꺼번에 제거할 수도 있다.
>>> list_b = [0, 1, 2, 3, 4, 5, 6]
>>> del list_b[3:6]
>>> list_b
[0, 1, 2, 6]
+ 범위의 한쪽을 입력하지 않으면 지정한 위치를 기준으로 한쪽을 전부 제거할 수도 있다.
>>> list_c = [0, 1, 2, 3, 4, 5, 6]
>>> del list_c[:3]
>>> list_c
[3, 4, 5, 6]
+ 리스트 슬라이싱
리스트[시작_인덱스:끝_인덱스:단계]
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8]
>>> numbers[0:5:2]
[1, 3, 5]
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8]
>>> numbers[::-1] #시작과 끝 인덱스는 자동으로 "전부"가 지정된다.
>>> [8, 7, 6, 5, 4, 3, 2, 1] #단계가 -1이므로 반대로 출력
* 리스트에 요소 제거하기 - 값으로 제거하기 : remove()
인덱스로 제거한다는 것은 '리스트에 있는 2를 제거'처럼 값을 지정해서 제거한다.
리스트.remove(값)
>>> list_c = [1, 2, 1, 2]
>>> list_c.remove(2)
>>> list_c
[1, 1, 2]
★ remove() 함수로 지정한 값이 리스트 내부에 여러 개 있어도 가장 먼저 발견되는 하나만 제거한다.
* 모두 제거하기 : clear()
리스트.clear()
* 리스트 정렬하기 : sort()
리스트.sort() #오름차순 정렬
리스트.sort(reverse=True) #내림차순 정렬
* 리스트 내부에 있는지 확인하기 : in/not in 연산자
값 in 리스트
>>> list_a = [273, 32, 103, 57, 52]
>>> 273 in list_a
True
>>> 99 in list_a
False
>>> 273 not in list_a
False
>>> 99 not in list_a
True
* for 반복문
for i in range(100):
print("출력")
* for 반복문 : 리스트와 함께 사용하기
for 반복자 in 반복할 수 있는 것:
코드
for character in " 안녕하세요":
print("-", character)

* 중첩 반복문
중첩 반복문은 일반적으로 n-차원 처리를 할 때 사용한다. [1,2,3]처럼 리스트가 한 겹으로 감싸진 리스트는 1차원 리스트, [[1,2,3],[4,5,6]]처럼 두 겹으로 감싸진 리스트를 2차원 리스트라고 부른다. 이처럼 n-차원 리스트 요소를 모두 확인하려면 ㅂ반복문을 n번 중첩해야한다.

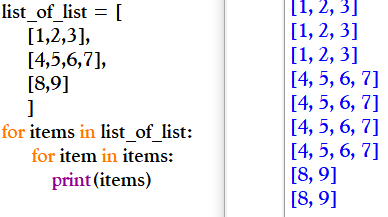
* 전개 연산자
전개 연산자를 사용하면 리스트 내용을 전개해서 입력할 수 있다. 리스트 앞에 * 기호를 사용한다.
ⓐ 리스트 내부에 사용하는 경우(코드를 비파괴적으로 구현 가능)
>>> a = [1,2,3,4]
>>> b = [*a, *a]
>>> b
[1,2,3,4,1,2,3,4]
ⓑ 함수 매개변수 위치에 사용하는 경우
리스트 안에 사용하는 것과 마찬가지로 리스트 요소를 하나하나 입력하는 것처럼 전개된다.
>>> a = [1,2,3,4]
>>> print(*a)
1 2 3 4
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ정리ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ

ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
<추가미션>
04-2 딕셔너리와 반복문
* 딕셔너리는 키를 기반으로 값을 저장하는 것이다. (리스트는 인덱스를 기반으로 값을 저장했음.)


* 딕셔너리 선언하기
변수 = {
키: 값,
키: 값,
...
키: 값,
}
>>> dict_a = {
"name" : "어벤져스 앤드게임",
"type" : "히어로 무비"
}
* 딕셔너리의 요소에 접근하기
>>> dict_a
{'name' : '어벤져스 앤드게임', 'type' : '히어로 무비'}
>>> dict_a["name"]
'어벤져스 앤드게임'
>>> dict_a["type"]
'히어로 무비'
#여기서 존재하지 않는 키에 접근하거나 값을 제거하려고 하면 KeyError 발생



위의 코드에서 ingredient는 dictionary의 키이기도 하지만, 여러 개의 자료를 가지고 있는 리스트이기도 하므로 다음과 같이 인덱스를 지정하여 리스트 안의 특정 값을 출력할 수도 있다.
>>> dictionary["ingredient"]
['망고', '설탕', '메타', '치자']
>>> dictionary["ingredient"][1]
'설탕' #망고가[0], 설탕이[1]
* 딕셔너리에 값 추가하기/제거하기
- 추가하기
딕셔너리[새로운 키] = 새로운 값
>>> dictinoary["price"] = 5000
>>> dictionary
{'name' : '8D 건조 망고', 'type' : '당절임', 'ingredient' : ['망고', '설탕', '메타중아황산나트륨', '치자황색소'], 'origin' : '필리핀', 'price' : 5000 } #마지막에 price키가 추가된걸 확인할 수 있음.
>>> dictinoary["price"] = 3000
{'name' : '8D 건조 망고', 'type' : '당절임', 'ingredient' : ['망고', '설탕', '메타중아황산나트륨', '치자황색소'], 'origin' : '필리핀', 'price' : 3000 } #딕셔너리에 이미 존재하고 있는 키를 지정하고 새로 값을 넣으면 기존의 값이 새로운 값으로 대치된다.
- 제거하기
>>> del dictinoary["price"]
{'name' : '8D 건조 망고', 'type' : '당절임', 'ingredient' : ['망고', '설탕', '메타중아황산나트륨', '치자황색소'], 'origin' : '필리핀' }
#del 키워드를 이용해 'price 요소' 다시 제거하기
* 딕셔너리 내부에 키가 있는지 확인하기 - ① in 키워드
딕셔너리에 존재하지 않는 키에 접근하면 KeyError가 발생한다. 따라서 키가 존재하는지, 존재하지 않는지 확인해야 한다 !
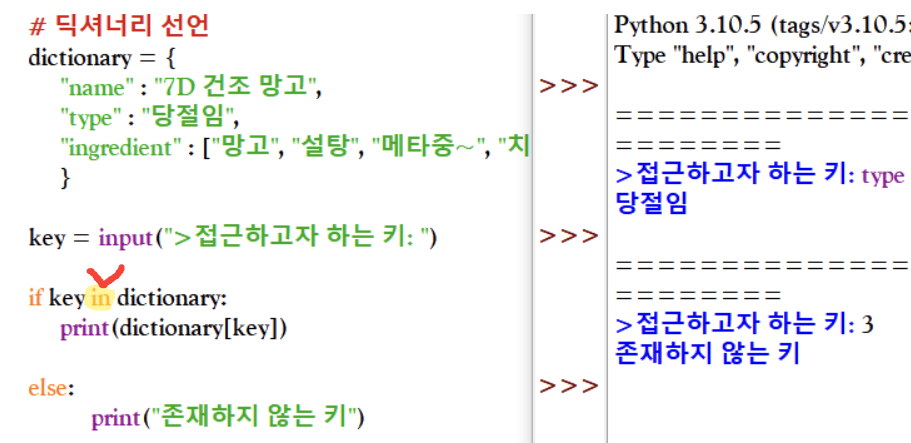
* 딕셔너리 내부에 키가 있는지 확인하기 - ② get() 함수
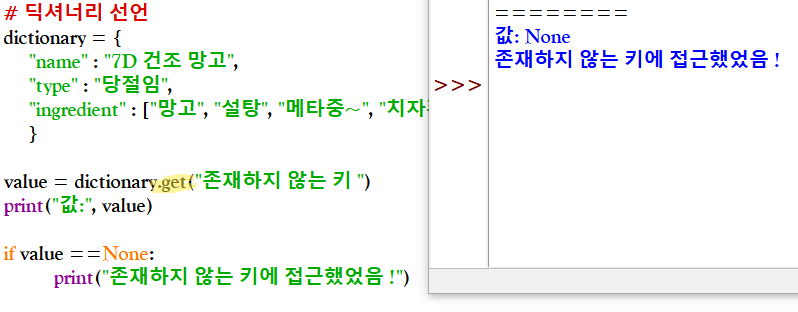
* for 반복문이랑 딕셔너리 같이 쓰기


04-3 범위 자료형과 while 반복문
* 범위 range() 함수
범위는 정수의 범위를 나타내는 값.
1) 매개변수에 숫자를 1개 넣는 방법
0부터 A-1까지 정수로 범위를 만들기 : range(A)
2) 매개변수에 숫자를 2개 넣는 방법
A부터 B-1까지 정수로 범위를 만들기 : range(A,B)
3) 매개변수에 숫자를 3개 넣는 방법
A부터 B-1까지 정수로 범위를 만드는데, 앞뒤의 숫자가 C만큼의 차이를 가짐 : range(A,B,C)
* list() 함수
1) 매개변수에 숫자를 2개 넣는 방법

2) 매개변수에 숫자를 3개 넣는 방법

* for 반복문 : 범위와 함께 사용하기
for 숫자 변수 in 범위:
코드

* for 반복문 : 리스트와 범위 조합하기

* while 반복문
while 불 표현식 :
문장
* while 반복문: for반복문처럼 사용하기

* while 반복문: 상태를 기반으로 반복하기

* while 반복문: 시간을 기반으로 반복하기
유닉스 타임 : 세계 표준시로, 1970년 1월 1일 0시 0분 0초를 기준으로 몇 초가 지났는지를 정수로 나타낸 것
>>> import time #유닉스 타임 구하기
>>> time.time()
4583532 #유닉스 타임값 나옴

* while 반복문: break 키워드 / continue 키워드
① break : break 키워드를 만나면 반복문을 벗어날 수 있음
② continue : continue 키워드를 만나면 현재 반복을 생략하고 다음 반복으로 넘어감
04-4 문자열, 리스트, 딕셔너리와 관련된 기본 함수
* 리스트에 적용 가능한 기본 함수 : min(), max(), sum() 함수

* 리스트 뒤집기 : reversed() 함수

* enumerate() 함수와 반복문 조합하기
리스트의 요소를 반복할 때 현재 인덱스가 몇 번째인지 확인해야할 때 enumerate() 함수 사용

* 딕셔너리의 items() 함수와 반복문 조합하기
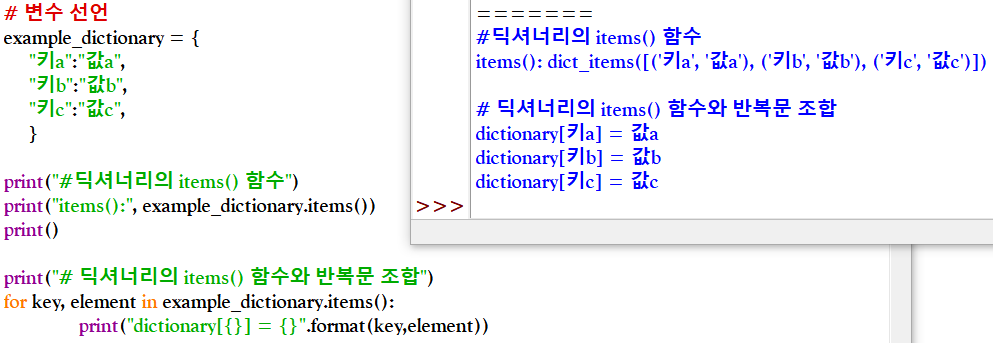
* 리스트 내포
리스트 이름 = [표현식 for 반복자 in 반복할 수 있는 것]
리스트 이름 = [표현식 for 반복자 in 반복할 수 있는 것 if 조건문]

+++ 여러 줄 문자열과 if 구문을 조합했을 때의 문제해결
1) 줄바꿈을 하려면 마지막을 제외한 문자열 뒤에 \n 입력
2) 문자열.join(문자열로 구성된 리스트)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ정리ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ

'파이썬' 카테고리의 다른 글
| 🐱🐉 혼공파 6주차 CH07-2~08 🐱🐉 (0) | 2022.08.16 |
|---|---|
| 🎁 혼공파 5주차 CH06~07-1 🎁 (0) | 2022.08.08 |
| 💟 혼공파 4주차 CH05 💟 (0) | 2022.07.31 |
| 💐 혼공파 2주차 CH2-3~03 💐 (0) | 2022.07.15 |
| 🌻 혼공파 1주차 CH1~2-2 🌻 (0) | 2022.07.09 |